Видео-теория: Анализ данных
Видео-урок
Сегодня мы начинаем видеокурс по подготовке к профилю «Технологии беспроводной связи» олимпиады НТО, тема занятия «Анализ и обработка данных».
Анализ данных, что это?
А что такое обработка данных, это когда мы берём некоторые данные и что с ними делаем?
Подумайте, что мы можем делать с данными?
К нам пришли некоторые данные. Мы ничего не можем прочитать, а что, собственно говоря, с ними делать?

Мы смотрим на эти данные видим какие-то буквы, символы, разделенные пробелами. Наверное, это слова. Мы точно знаем, что в письменности пробелы разделяют слова.

У нас получилась такая картина, что мы смогли отделить, так называемые слова. Что мы ещё видим мы видим знаки препинания. И тоже их отделили и получилась структура. У нас есть символ переноса строки, разделитель частей предложения (запятые) и символы окончания предложения (точки).

Дальше, если мы это все структурируем, то видим, что в каждом предложении есть три слова, неважно на каком языке написано, дальше эту структуру можем представить в виде дерева и понять, что нам удалось спарсить данные.

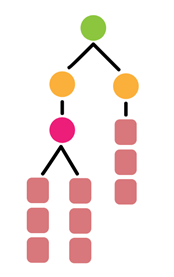
Если на реальном примере посмотрим, то получим следующее, к нам пришли какие-то данные.

Мы видим знаки переносов строк, выделенные шесть строк и также в конце поставлен знак завершения данных.

Теперь в каждой строке мы увидим, что есть какие-то знаки точка с запятой, наверное, это разделители. Мы это учли, мы разделили данные и увидели, что в каждой строке есть по четыре таких кусочка.
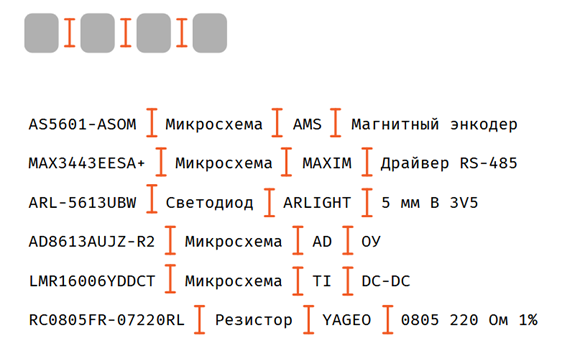
Интересно, что же дальше можно сделать. Если мы расставим всё, как и в прошлом примере, то получим следующее, что есть шесть строчек и четыре столбика, то есть это обычный табличный формат.
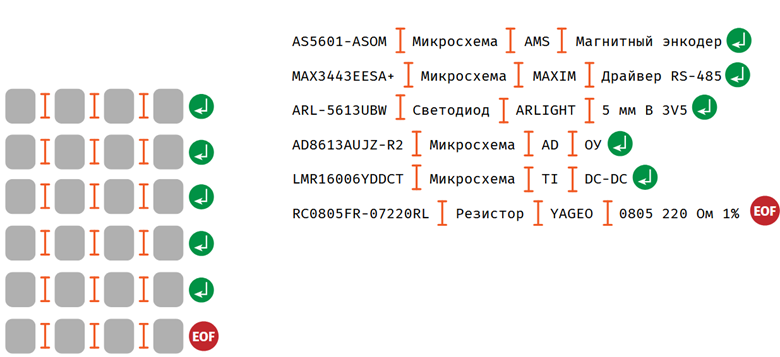
На самом деле это табличный формат CSV, и в результате у нас получилась такая таблица, состоящая из четырёх столбцов и шести строк. И это все реальные данные!
Резюмируя, анализ данных, как проходит:
- Сначала данные нужно создать. Нет данных — нет анализа.
- Данные нужно получить. Нет данных у нас — нет анализа.
- Данные нужно избавить от ошибок. Не всегда легко.
- Восстанавливаем изначальную структуру данных, как она была задумана тем, кто данные формировал.
- Ищем в данных информацию. Часто это исключительные значения, закономерности, запрещённые сочетания значений, и многое другое.
Идеальная ли это структура?
При анализе данных стоит задуматься, может мы что-то не учитываем, может вообще мы живём, не в реальном мире и все нормально пройдёт.
Зачастую данные приходят в непонятном формате. у них есть связи, которые мы не понимаем, что это такое, и какие это связи. Непонятно, что происходит, как анализировать это.
Потому мы возьмём немного другой алгоритм, когда данные формируем и перед отправкой, нам нужно эти данные ещё сжать, то есть как-то закодировать, чтобы, во-первых, защитить от лишних глаз, во-вторых, передать с минимальными потерями.
Дальше мы должны изучить эти данные и понять вообще, что там происходит, какая там структура почему нам эти данные пришли. Допустим нам пришел какой-то график, точнее набор чисел для графика.
Там что-то происходит и происходит непонятное, нужно вообще выделить, а что нам из этого пригодится. Другими словами, найти признак, который будем анализировать. Поэтому эти признаки мы должны как-то отделить, выделить и пометить.
Дальше мы должны перейти к передаче данных, если мы зашифруем эти слова, их передадим, что мы получим?
Мы сначала получим шифрованные значения, дальше нам нужно распаковать шифрование значения, но для этого нам нужны ключи. И вот какая ситуация может произойти. Распаковали и получили следующий текст:
Дело былп вечером,
делать было нечшго
Для избежания таких казусов, используют защиту от ошибок, просто так передавать данные плохо, есть риск ошибочных значений, чтобы этого избежать, мы подставляем контрольное значение и, когда данные придут, можно сверить приходящие данные с контрольным значением и радоваться, если все сошлось.
Также мы можем исправить ошибку, отправив дополнительно данные, но мы не сможем защитить данные. Потому что избыточность данных нужно использовать с умом. С помощью методов самокорректирующихся кодов, контрольных сумм и прочего.
Переходим к изучению данных
Нам нужно задаться парой вопросов. А что происходило в тот момент, когда данные формировались нормальные ли там условия, все стабильно ли работало?
Тот же дождь влияет на ошибки дальше.
Каковы были помехи, то есть, допустим, если мы записывали звук и передавали какую-то информацию. И, когда она формировались, были помехи, может там какой-нибудь человек шумел или комар рядом летал и создавал шум, из-за этого данные чуть-чуть искажаются и нам нужно будет их почистить.
А вообще, что должно на этих данных происходить, что мы анализировать должны, то есть это данные по солнцу или это данные какие-то звуковые, шелест листиков и вообще реальные ли это данные?
И всё это при анализе мы должны учитывать. Подведём итоги, анализ данных — это их изучение, формирование, сжатие, защита и передача.